Les 84 caractères de l'alphabet français
À chaque nombre, son caractère
Il important de garder à l'esprit qu'un texte enregistré est ... codé !
En effet, un ordinateur est incapable d'enregistrer des lettres et même des
chiffres ! ...
Tout fichier - texte, image, musique, vidéo, programme, ... - n'est qu'un ensemble d'octets. Et, un octet est une série de 8 bits. Un bit étant une information binaire de type oui-non, haut-bas, vrai-faux. On représente cette information sous la forme de 0 (zéro) ou 1 (un).
NB : L'ordinateur est la plus bête machine qui soit. Il n'enregistre que deux types d'information. Mais sa force est qu'il est capable de lire plusieurs millions de bits par seconde.
Une série de 8 bits permet identifier 256 nombres (allant de 0 à 255).
0000 0000 = 0
0000 0001 = 1
0000 0010 = 2
0000 0011 = 3
0000 0100 = 4
0000 0101 = 5
0000 0110 = 6
0000 0111 = 7
...
0111 1111 = 127
1000 0000 = 128
1000 0001 = 129
...
1111 1110 = 254
1111 1111 = 255
On sait qu'il n'existe que 26 lettres minuscules, 26 lettres majuscules, 10 chiffres, quelques signes de ponctuations, ... Bref, on constate qu'on utilise, au total, moins de 95 caractères (non accentués) pour écrire.
Or, une série de 8 bits permet d'identifier 256 nombres (et donc 256 caractères, si on attribue à chaque nombre un caractère). C'est donc amplement suffisant pour tout anglophone.
Les américains et les anglais n'utilisent pas de caractères accentués.
Et, l'informatique, au début, a été inventé par des américains ...
Il suffit alors de définir une table de conversion, d'attribuer à chaque nombre un caractère. La plus connue est la table ASCII ( où seuls les 128 premiers nombres correspondent à un "code", les 128 autres nombres (tous les octets dont le bit de gauche est 1) n'ont pas reçu de signification.)
Les nombres entre 0 et 31 correspondent à des caractères de contrôle tel que le retour à la ligne.
Les 95 nombres entre 32 et 126 (compris) sont des caractères imprimables et attribués aux chiffres, aux lettres minuscules et majuscules (non accentuées) et caractères spéciaux, tel que les caractères de ponctuation, d'arithémtique (+ * - / % =), ...
Le nombre 127 correspond à un code (DEL)
Extrait de la table ASCII
0000 0000 = 0 représente NULL
...
0011 0000 = 48 représente 0
0011 0001 = 49 représente 1
...
0100 0001 = 65 -> A
0100 0010 = 66 -> B
...
0110 0001 = 97 -> a
0110 0010 = 98 -> b
...
0111 1111 = 127 -> DEL
NB : L'espace entre les séries de 4 bits n'est là que pour rendre l'octet plus lisible.
Une table complète (où les nombres entre 128 et 255 sont attribués aux caractères accentués et très spéciaux) s'appelle table ASCII-étendu. Or, une table ASCII-étendu ne suffit pas pour tous les caractères de toutes les langues du monde. Pour chaque version, on a donné un nom différent. En Europe : Latin-1, Latin-2, ...
Si vous parliez "ordinateur", vous diriez :
0011000100101011001100010011110100110010
pour dire : 1+1=2
NB : Ce qui est enregistré est toujours un nombre de bits divisible par 8.
01000010010011110100111001001010010011110101010101010010
pour dire : BONJOUR
Ce qui est enregistré sur le disque dur sont les suites de 0 et 1.
Ce que vous voyez à l'écran n'est que la traduction de ces suites de 0
et 1, selon une table de conversion.
Heureusement, l'ordinateur est capable de décoder des millions d'octets par seconde.
NB : Coder signifie stocker sous un format, ici, binaire.
Décoder = transformer le format binaire en données exploitables (lisibles, audibles,
exécutables, ...)
Les caractères bizarres
Tout ceci pour vous expliquer pourquoi parfois est affiché à l'écran des caractères bizarres à la place des caractères accentués. C'est dû à un mauvais choix de la table de conversion.
Toutes les tables (ASCII, UTF-8, Latin-1, Latin-9, ...) sont identiques pour les 128 premières définitions. Ouf ! C'est après que cela se complique ...
NB : Les anglophones n'utilisent pas de caractères accentués.
Conséquence : ils ne voient jamais de caractères bizarres sur leur écran.
Mais, tout le monde ne parle pas anglais ! ...
Une table de conversion encore souvent utilisée en Europe occidentale ( Belgique, France, ...) se nomme officiellement ISO 8859-1, souvent appelée Latin-1. Depuis le passage à l'euro, la table de conversion par défaut des navigateurs web est Latin-9, officiellement ISO 8859-15.
Comment sont codés les caractères accentués ?
Tout dépend de la table choisie ...
En Latin-1 (et en Latin-9): é -> 11101001
En UTF-8, : é -> 11000011 10101001
L'espace entre les deux octets n'est là que pour la lisibilité.
En réalité, il n'existe aucun espace entre les 0 et 1.
En UTF-8, le é est codé sur 2 octets !
Que se passe-t-il si ce caractère (é) est enregistré (codé) en UTF-8 (par exemple, via le Bloc-notes) mais lu (décodé via un navigateur-web) en utilisant la table Latin-1 ou Latin-9 ?
En latin-1 ou Latin-9, chaque octet correspond à un caractère.
Le navigateur web affichera donc 2 caractères !
Lesquels ?
En Latin-1 (ou Latin-9) : 11000011 -> Ã
En Latin-1 (ou Latin-9) : 10101001 -> ©
Tous les é seront affichés é !
Or, dans la langue française, il existe 16 caractères accentués ... (et deux ligatures)
Choix de la table
Pourquoi le programme qui lit le fichier peut-il se tromper dans le choix de la table de conversion ?
Parce qu'un fichier texte TXT est un "bête" fichier ! Son contenu ne contient que le texte ... et donc pas le nom de la table de conversion utilisée lors de son enregistrement. Or, le programme qui lira le fichier ne sera pas nécessairement le même que celui qui l'a créé ...
Puisque vous êtes en Europe occidentale (Belgique, France, ...), les navigateurs web considèrent que la table à utiliser, en absence d'instruction précise, est Latin-9 ...
Affichage d'un fichier TXT dans un navigateur :
-
codé en UTF-8 (noter tous les caractères bizarres, car votre navigateur a choisi la table Latin-9 )
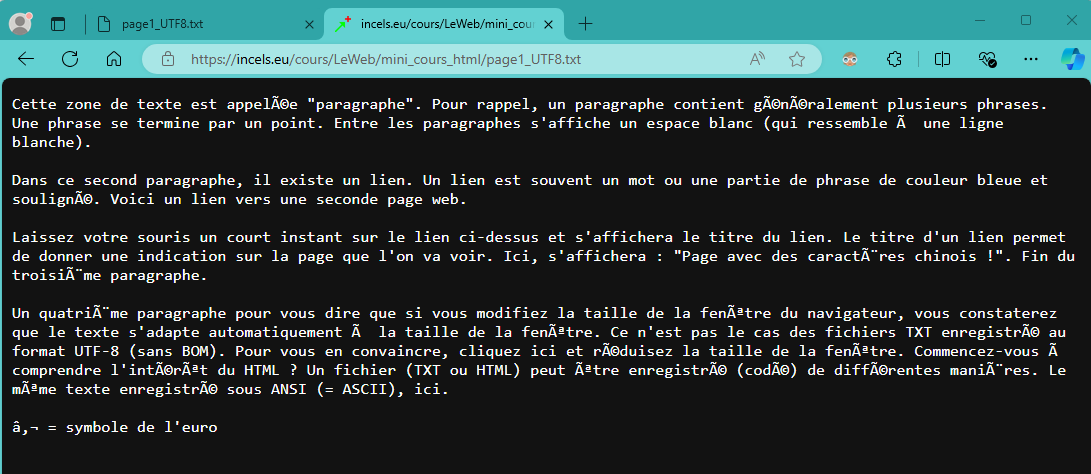
Fichier en ligne 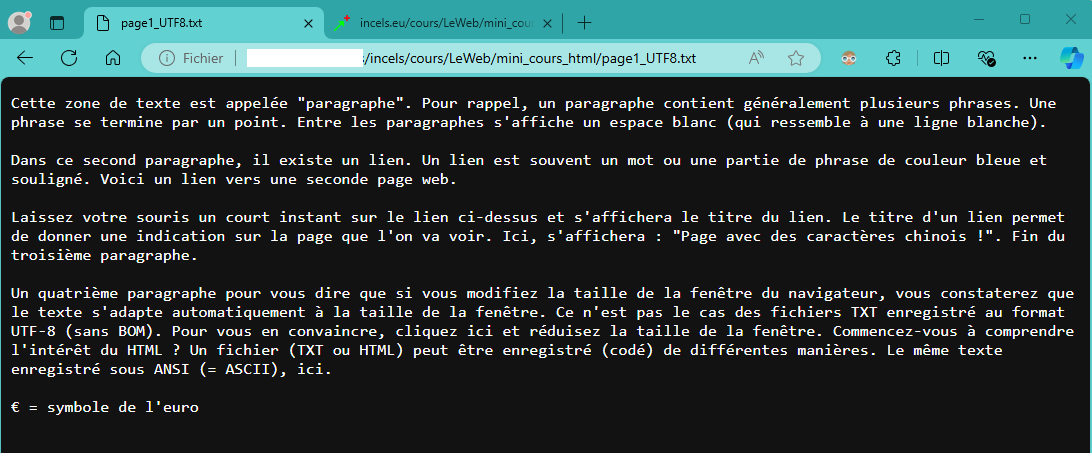
Fichier sur le disque dur Même fichier, même navigateur ... mais deux affichages différents !
Dans le premier cas, le fichier provient d'un serveur.
Dans le second cas, le fichier provient du disque dur. - codé en ANSI (noter que, sur la dernière ligne, le symbole de l'euro s'affiche correctement, car votre navigateur a choisi la table Latin-9)
Fichier intelligent
Un fichier intelligent ne contient pas que le texte ...
Un fichier intelligent contient d'autres informations au début du fichier, appelées
méta-données.
En HTML, elles sont placées dans le head.
Le fichier HTML est "intelligent", mais VOUS pouvez faire une bêtise ...
Exemple. Si vous enregistrez le fichier HTML en se basant sur UTF-8, mais que vous indiquez dans le head <meta charset="ISO 8859-1" /> (ou que vous omettiez cette balise), des caractères bizarres remplaceront les caractères accentués.
Fichier "bête"
Les fichiers pouvant être lus dans un éditeur de texte et n'indiquant pas l'encodage qui a été utilisé peuvent être mal décodés par le navigateur. Tels que les fichiers au format : texte (*.txt), javascript (*.js), python (*.py), ...
Encodage du code
Si vous publiez des fichiers encodés en utf-8, tel que du code source, (*.js, *.py, ...), du texte (*.txt), des données (*.csv), ...
-
Créer ou modifier le fichier
.htaccess(par exemple, celui à la racine du site), afin d'y ajouter les directives suivantes :AddCharset UTF-8 .py AddCharset UTF-8 .js
Pour que tous les fichiers .py et .js soient envoyés au client avec le jeu de caractères UTF-8.
-
Et/ou ... dans le fichier publié, prévenir vos visiteurs que les caractères accentués et spéciaux peuvent être mal affichés dans un navigateur web. Sans cet avertissement, ils peuvent avoir des doutes sur la qualité de votre publication. Après cet avertissement, invitez-les à télécharger au lieu de le lire.
Conclusion
Si on voit des caractères bizarres sur une page web, la raison est qu'il a été codé sur base d'une table de conversion différente de celle utilisée pour le lire.
Il faut enregistrer un fichier HTML en utilisant la même table de conversion que celle déclarée dans le head. La bonne solution, en HTML, toujours choisir UTF-8.
Encoder les autres fichiers texte (*.txt, *.js, *.py, *.csv ...) en ANSI, Latin-1, Latin-9, ... pour éviter des problèmes d'affichage serait une erreur, car l'UTF-8 présente trop d'avantages.
Le premier avantage de l'UTF-8 est qu'il n'est plus nécessaire de choisir la table de conversion.